
Why Your Context Should Not Always Repeat Itself
Recency is one of the strongest ranking signals in any memory system. When you're building recall for teams or agents, the latest interactions often feel like the safest bet because they're fresh, relevant, and likely closer to the user's current intent.
But recency can also create a subtle failure mode: if the last few interactions all orbit the same topic, the top of your recall stack becomes an echo chamber. Queries like "What dishes do I like to eat?" end up dominated by a single restaurant simply because those entries are both recent and similar. Technically correct, practically useless.
When recency overwhelms representation
Consider a food-preference query with a heavily skewed recent history. Without any diversification, the top results might look like this:
- Ippudo / Thai Express / Chipotle preference summary
- Burritos from California Burrito
- Mexican Rice Bowl at California Burrito
- Meghana Biryani
- Cheese Quesadilla at California Burrito
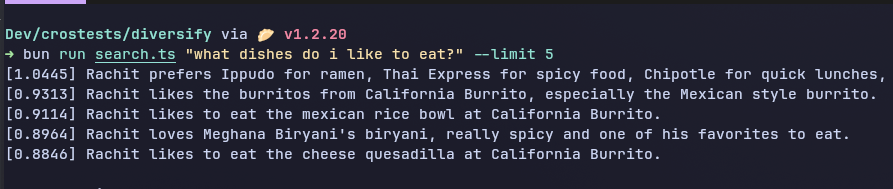
Three out of the first five memories point to the same restaurant. The agent learns that the user really loves California Burrito, but it loses broader coverage of the user's taste. The retrieval is accurate yet not representative.
Diversify with Maximal Marginal Relevance
To keep recency without sacrificing coverage, we introduce Diversify, a post-ranking step based on Maximal Marginal Relevance (MMR). MMR balances two competing objectives for every memory we promote into the final result set:
- How relevant the memory is to the query.
- How similar it is to memories that have already been selected.
A candidate that is highly relevant but nearly identical to something we've already kept gets down-weighted, creating room for a different - yet still relevant - memory to surface.
With Diversify applied, the same query returns a spread that still includes California Burrito, but also highlights Indori Poha, Meghana Biryani, and Thai Express. Freshness remains intact; redundancy does not.

Lightweight post-processing
Diversify slots in after retrieval and reranking, right before we commit to the final top_k. By this stage we already have high-quality candidates. The goal is no longer finding relevance, it's allocating it.
- No additional LLM calls are required.
- Memories remain untouched - Diversify only changes ordering, not content.
- The step is deterministic and fast, so it scales alongside existing search pipelines.
Using Diversify in the API
import Crosmos from "crosmos";
const client = new Crosmos();
const results = await client.search.hybrid({
query: "food preferences",
space_id: "019dc652-2724-76d6-ab4b-1b2d077019b5",
limit: 10,
rerank: true,
diversify: true, // MMR to reduce redundancy
graph: true, // include graph signal
});
Setting diversify: true enables MMR. Everything else in your pipeline stays the same.
Where Diversify shines
- Exploratory search – Browse a memory space without seeing five versions of the same event.
- Summarization – Provide agents with representative evidence instead of wasting tokens on duplicates.
- Pattern discovery – Surface varied signals when spotting trends across preferences or workflows.
- Agent context – Keep prompts balanced so downstream reasoning isn't biased toward one entity.
- Long-term memory – As spaces grow, clusters form; Diversify keeps breadth without diluting relevance.
Final thoughts
Relevance alone is not enough. When multiple strong matches are basically mirror images, the agent learns less even though recall scores look perfect. Diversify keeps recency, protects coverage, and stops your context window from echoing itself. Your memory stack should highlight what matters next, not repeat what mattered last.